


Data-driven VC #19: Value accrual in the modern AI stack
Where venture capital and data intersect. Every week.

👋 Hi, I’m Andre and welcome to my weekly newsletter, Data-driven VC. Every Thursday I cover hands-on insights into data-driven innovation in venture capital and connect the dots between the latest research, reviews of novel tools and datasets, deep dives into various VC tech stacks, interviews with experts and the implications for all stakeholders. Follow along to understand how data-driven approaches change the game, why it matters, and what it means for you.
Current subscribers: 4,913, +270 since last week
This post was written by my colleagues
, Laurin Class and me and was originally published on the Earlybird blog. Following your continuous interest in my previous ChatGPT-related posts (“10x your productivity with ChatGPT” and “What ChatGPT means for startup funding”) and the positive feedback on our original Medium post, I am reposting it here for the Data-driven VC community.“There are decades where nothing happens; and there are weeks where decades happen” — Lenin
Over the last few years, one seismic event after another elicited a recitation of Lenin, so much so that at some stage it felt like screaming into the void, most of us desensitized.
Scientific breakthroughs, though, still have the power to grip us like nothing else. The sheer euphoria with which people are reacting to the latest advances in transformer-based large language models is deafening. Most of the commentary is incredulous at the colossal steps AI has taken this year.



It’s hard to resist the feeling that we’re in the early innings of a profound technology shift, with a starry eye toward the horizon of what’s possible in the future.

In a relatively short span of time, investors have already amassed volumes of analysis on the antecedents to AI’s current moment. Top of mind for investors, though, is the question of capital allocation: Which components of the AI ‘value chain’ are most attractive for VCs?
With a market that’s evolving at such a ferocious pace, any conclusions will rest on a bedrock of assumptions. Despite the incredibly captivating power of models today, we’re still in the early innings of the revolution. What we can do is simulate different moves on the chessboard and assign probabilities to each outcome, which ought to give us some foresight into the winners in the AI value chain.
The State Of Play
Research into machines that are capable of emulating human intelligence dates back to the 1950s. Many Gartner hype cycles followed and faded, but research kept ticking along, compounding, with each subsequent breakthrough building on top of the corpus of predecessors.

Through these cycles, there was a gradual shift from scholarly publications and academia to private investment from commercially oriented organizations. The preceding decade saw the formation of several research labs from both incumbents (e.g. Google, Meta) and startups (e.g. OpenAI), each mobilizing vast compute and data resources to advancing ML; the inflection in research papers that followed is clear to see.

Two milestones account for much of the inflection that coincided with the emergence of the research labs. The first was in 2012, when Alex Krizhevsky of the University of Toronto demonstrated the superiority of deep learning neural networks over state-of-the-art image recognition software, having trained the model on GPUs that were capable of handling trillions of math operations. From this point onwards, ML models had the computational capacity to scale, leveraging the advantageous properties of GPUs such as parallelism to perform compute-intensive tasks like matrix multiplication that are at the core of AI models. GPUs are leaps ahead of others ASICs like Google’s TPUs in terms of market share (within GPUs, Nvidia has the lion’s share of the market, but more on that later), despite TPUs being better for the training of many models. In short, GPUs unlocked a new paradigm of computing capacity.
The second catalyst was the publication of a landmark paper in 2017 by a team of researchers from Google. The paper outlined a new architecture for deep learning models that relied on attention mechanisms in a novel way, eschewing previous methods (recurrent networks) to deliver superior performance. Transformer-based models lend themselves to parallelism and are therefore able to derive maximum value from GPUs, requiring less time to train. These two seminal developments culminated in Transformer-based ML models flourishing ever since, incurring significantly more compute to scale.


Notably, although the initial applications of Transformers were focusing on Natural Language Processing, recent academic papers on transformers give ample evidence of how transformative (excuse the pun) this architecture is across different modalities beyond text generation.
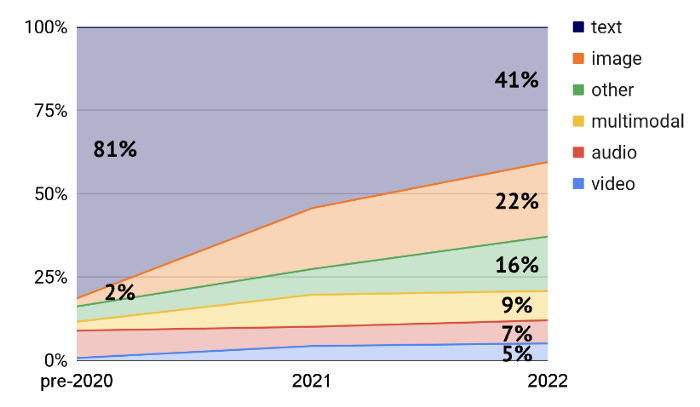
When we extrapolate the post-Transformer trajectory of model performance into the future (without allowing for further breakthroughs in compute or model architectures), it’s no wonder that AI is being heralded as the next platform shift after personal computing, mobile, and the cloud.
Our perception of technological advancement is often too linear, extrapolating based on past growth rates, preventing us from grokking exponential change when it’s before us.

That naturally leads us to underestimate the range of future outcomes, diluting the truly plausible and preposterous future scenarios for AI’s development and its impact on humanity.

Weighing these outcomes against probabilities directly translates to investment theses on how the AI value chain will evolve, where the long-term value capture will be, and commensurately where the biggest companies will be built.
Infinite Possibilities
The AI vendor landscape does not neatly conform to a value-chain framing, because all of the components bleed into each other to varying degrees — a dynamic that’s only likely to further accentuate over time.
That said, this framing from Evan Armstrong covers the general contours of the technologies behind today’s applications:
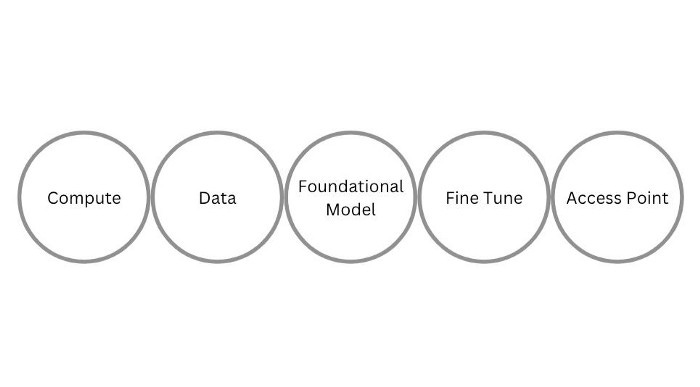
Compute powers the foundational model research companies that train their models on huge volumes of data, to deliver a pre-trained transformer model to the builders of applications. These application builders may elect to fine tune the model with domain specific data to derive superior performance for specific applications that serve as access points to AI for the general population.
To begin answering the question of long-term value capture, we first have to determine the conditions in which these companies will be operating. One of the most important variables that will dictate any specific company’s propensity to venture upstream or downstream of itself in the value chain is Total Addressable Market (TAM). The framing we can use to think about this is:
The total value creation attributable to AI is large enough to accommodate X categories (infrastructure & application-level) and that each produces X billion in revenue
If the total value creation is insufficient to support a multitude of categories, which component of the value chain is best equipped to move upstream or downstream to capture more value
Let’s take the analogy of data infrastructure. The shift from on-prem to cloud spawned numerous categories oriented around getting data into production and deriving value.